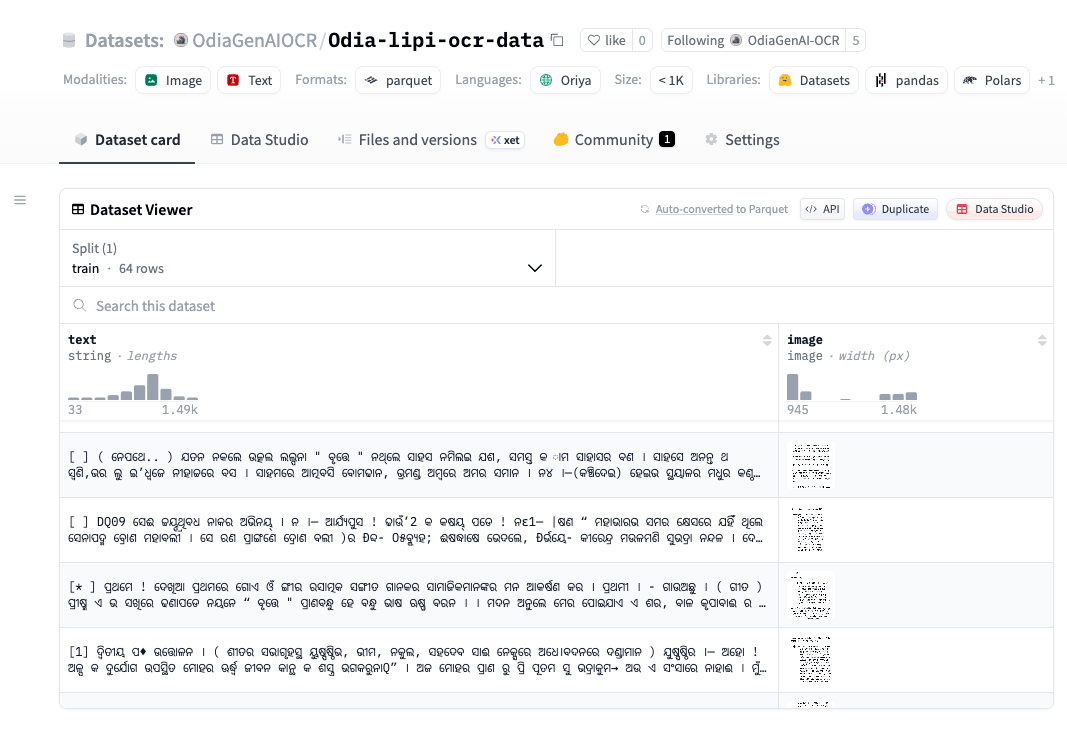
Odia is a low-resource Indic language with limited support for Optical Character Recognition (OCR). Existing OCR systems struggle with both printed and handwritten Odia text, and none perform reliably on handwritten documents.
Most Odia literature, newspapers, and historical manuscripts exist in palm-leaf manuscripts, scanned images, or physical formats, making them difficult to digitize, search, and process.
Key challenges:
- Complex Odia ligatures and diacritics are hard for current OCR systems to recognize.
- Limited datasets for training modern OCR models.
- Lack of open-source, high-accuracy OCR tools.
- Handwritten Odia text is largely unsupported by existing solutions.
Without a robust OCR system, Odia text remains inaccessible for digital archiving, computational analysis, and language technology applications.